

Games have a track record of solving hard technical problems before anyone else needs to. GPUs exist because games needed faster rendering. Then those same chips turned out to be exactly what AI needed, and now they run the whole industry.
Something similar is happening with version control. Games deal with huge files, lots of people working in parallel, code mixed with 3D assets, audio, engine configs. That's why we built Diversion: the existing tools couldn't handle it.
With AI code assistants like Claude Code, Cursor, and Codex, software developers are running into a similar problem. Agents do what humans do, but at a bigger scale: more speed, more actions like commits, PRs, and code changes. So the tools that were great are now becoming a bottleneck for innovation.
The benchmark
We ran a head-to-head test comparing GitHub and Diversion under identical conditions. Same file count, same file size, same commit rate, same load generator. Concurrent users committing to the same branch, scaling from 20 to 100 users.
The results:
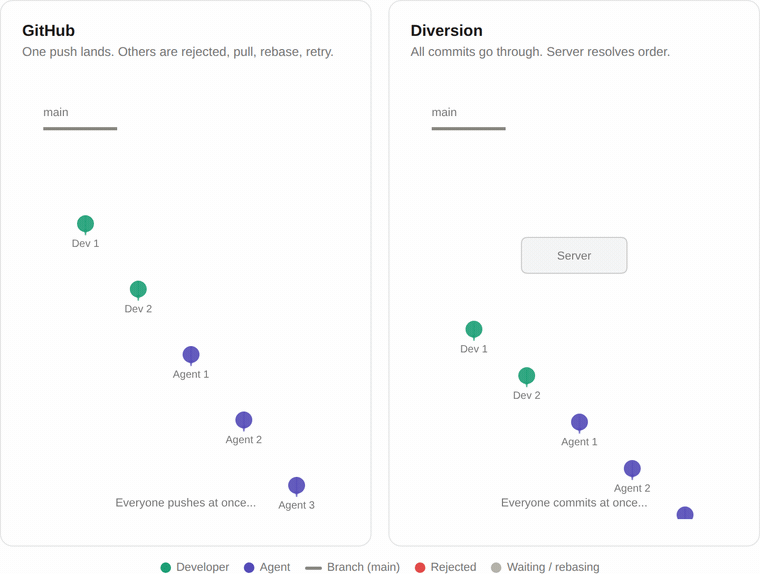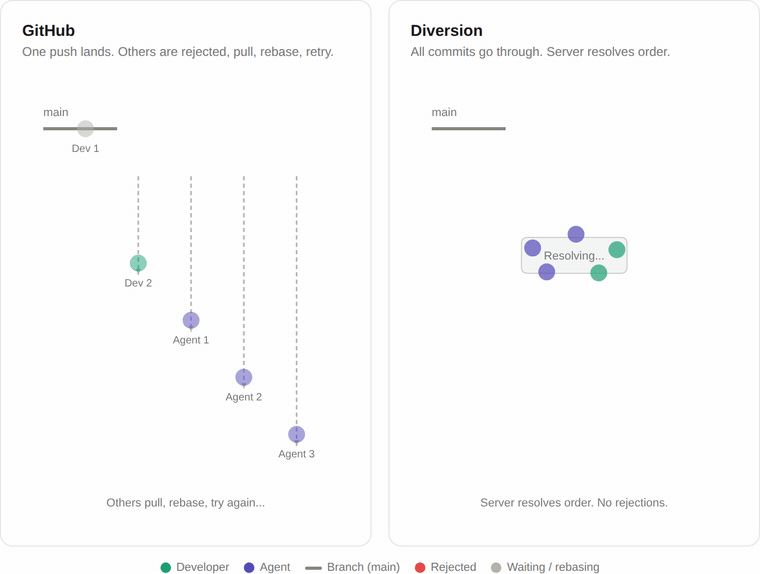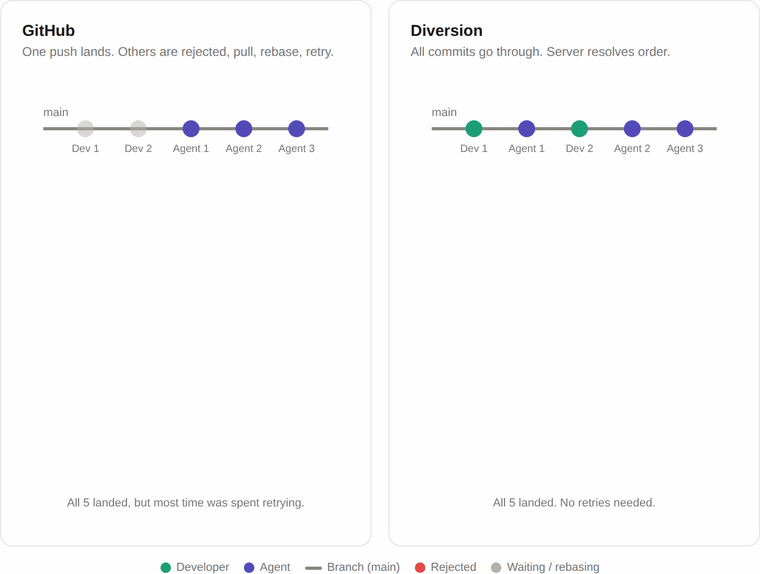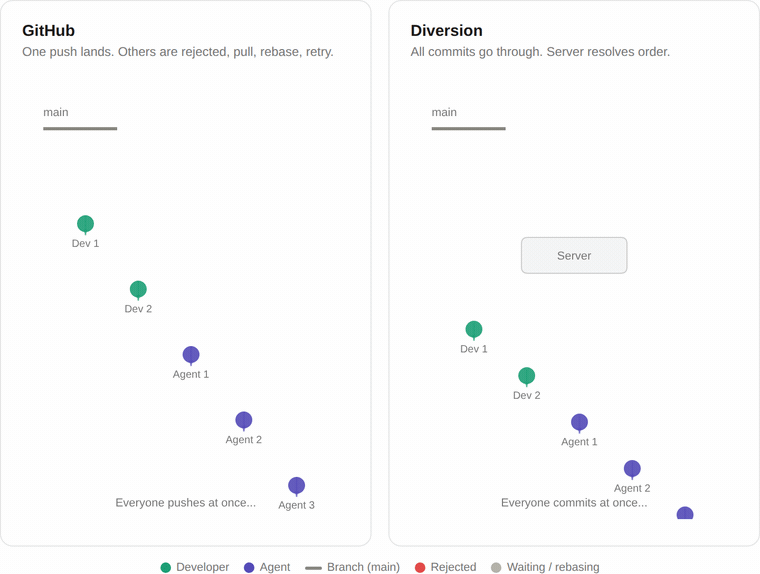
GitHub plateaued at roughly 30 commits per minute regardless of how many users we added. The test had to stop at 60 users because the git worktrees exhausted disk space. Diversion scaled linearly to 300 CPM at 100 users, and we stopped the test there, not because we hit a limit, but because we'd made our point.
30 commits per minute was fine when humans were the only ones committing. It's not fine when a team of agents is working alongside them.
Why GitHub hits a ceiling
Git was designed so that only one change can land on a branch at a time. When you push, Git checks if anyone else pushed before you. If they did, your push is rejected. You have to pull their changes, rebase yours on top, and try again.
When it's just a few people, this works fine. But as more developers and agents push at the same time, almost every push collides with someone else's. Everyone ends up in a retry loop, and the actual throughput flatlines.
In our test, GitHub couldn't get past ~30 commits per minute no matter how many users we added. It's not a resource problem. It's how Git works. No amount of server hardware fixes it.
Why Diversion scales
We don't use Git's locking model. Commits go through an API that handles conflicts on the server side, so there's no retry loop on the client. If two people commit at the same time, they both go through.
That means throughput scales with infrastructure: more backend capacity, more commits per minute. In the same test, Diversion reached 300 commits per minute at 100 concurrent users, and we stopped the test there, not because we hit a wall, but because we'd made our point. The ceiling is ours to raise.
What this means for your team
AI agents are changing how code gets written, and not gradually. The workflow is shifting from big, carefully staged pull requests to smaller, more directed commits landing continuously. The tools need to keep up.
We built Diversion for game development, where this kind of scale was already a reality. It turns out, with AI agents in the picture, every team is a game-sized team now.



